Abstract
Cloud storage has transformed the way organizations manage, store, and access data. Its scalability, availability, and automation have made it the backbone of modern IT infrastructure. However, the architectural complexity of cloud storage—combined with advanced redundancy techniques—presents significant challenges for data governance, cost control, and, critically, secure data deletion. This paper explores the layered architecture of cloud storage systems, the role of redundancy in ensuring availability, and the unintended consequences of these designs on data lifecycle management.
1. Introduction
Cloud storage systems promise convenience and resilience through abstraction, automation, and replication. These attributes are indispensable for supporting global-scale services and ensuring business continuity. However, beneath this abstraction lies a complex architecture that disperses data across physical and logical boundaries. For cybersecurity professionals and data compliance officers, this architectural opacity can hinder effective data management and sanitization, especially in the context of regulations like GDPR, HIPAA, and industry guidelines such as NIST SP 800-88 Rev. 1.
2. Core Components of Cloud Storage Architecture
Cloud storage systems are typically built using a multilayered model that includes:
-
Storage Virtualization Layer: Abstracts physical storage resources and presents logical volumes or buckets to users.
-
Metadata and Indexing Engines: Manage access controls, retrieval efficiency, and versioning.
-
Replication and Backup Services: Create redundant copies for fault tolerance.
-
Caching and CDN Integration: Optimize speed and latency for distributed access.
-
Snapshot and Version Control: Automatically retain historical states of stored data for rollback or compliance.
These components work in tandem to deliver high availability and durability—but also result in multiple, often hidden, copies of data.
3. The Role and Complexity of Redundancy
Redundancy in cloud storage ensures that data remains accessible even in the face of hardware failure, natural disaster, or cyberattack. Key redundancy strategies include:
3.1 The 3-2-1 Backup Rule
This industry-standard approach recommends:
-
3 copies of your data
-
On 2 different media
-
With 1 copy off-site
Though originally intended for on-premise backup, cloud platforms often implement this philosophy by:
-
Replicating data across data centers (Availability Zones)
-
Storing redundant blocks in erasure-coded formats
-
Maintaining geo-replicated disaster recovery environments
3.2 Cross-Zonal Replication
Services like AWS S3 Cross-Region Replication or Azure Geo-Redundant Storage (GRS) automatically synchronize data between distant geographic locations. While beneficial for uptime, such replication significantly complicates efforts to achieve total data sanitization.
3.3 Immutable Backups and Snapshots
Many cloud platforms offer point-in-time snapshots or immutable backups for compliance or ransomware recovery. These often persist beyond user deletion and are invisible to the user-facing interface.
4. Implications for Data Governance and Sanitization
The architectural complexity described above makes simple deletion actions misleading. When a user deletes a file or object:
-
The primary instance may be removed from active storage.
-
However, replicas, caches, logs, indexes, and backups may continue to contain that data.
-
Redundant systems, especially those with eventual consistency models, may reintroduce deleted data unintentionally.
This introduces “residual data risk”—the possibility that deleted data persists in unknown or inaccessible layers of the system.
NIST 800-88 warns against such ambiguity and recommends:
-
Understanding the full lifecycle of storage media and systems
-
Applying cryptographic erasure when physical destruction is not possible
-
Ensuring all replicas and backups are sanitized when decommissioning data
5. Case Scenarios of Complexity-Induced Risk
5.1 Cloud-to-Edge Sync
In hybrid models (e.g., syncing data from OneDrive or Google Drive to local devices), deleted files may survive in edge caches or offline folders.
5.2 Orphaned Snapshots
If a virtual machine is deleted but its snapshot is retained (common in VMware, AWS EC2), the data technically remains recoverable.
5.3 Multi-Tier Storage Systems
Systems like AWS S3 move data between Standard, Infrequent Access, and Glacier tiers. A deleted file in the Standard tier may still exist in Glacier if part of a backup policy.
6. Recommendations for Managing Complexity
To navigate the architectural complexity of cloud storage effectively, organizations should:
-
Maintain Storage Mapping: Track all data locations, versions, and redundancies.
-
Use Key-Based Encryption: Adopt encryption-at-rest with customer-managed keys to enable cryptographic erasure.
-
Implement Data Lifecycle Policies: Define retention, expiration, and deletion rules across all tiers and services.
-
Audit and Monitor: Continuously review backup policies, replication settings, and deletion logs.
-
Partner with Providers: Request documentation and verification of deletion practices, especially in regulated industries.
7. Conclusion
Cloud storage architectures are inherently complex by design—and rightly so, given the scale and performance demands of today’s data-driven world. However, this complexity introduces significant challenges to data governance, particularly around secure data deletion and compliance. Redundancy, while essential for resilience, must be counterbalanced with mechanisms that provide users full visibility and control over the data lifecycle.
As data privacy regulations tighten and organizations become more security-conscious, the need for transparent, verifiable, and complete data sanitization in cloud environments will only grow. Understanding and managing cloud storage architecture is no longer just a matter for DevOps—it is a central pillar of trustworthy digital infrastructure.


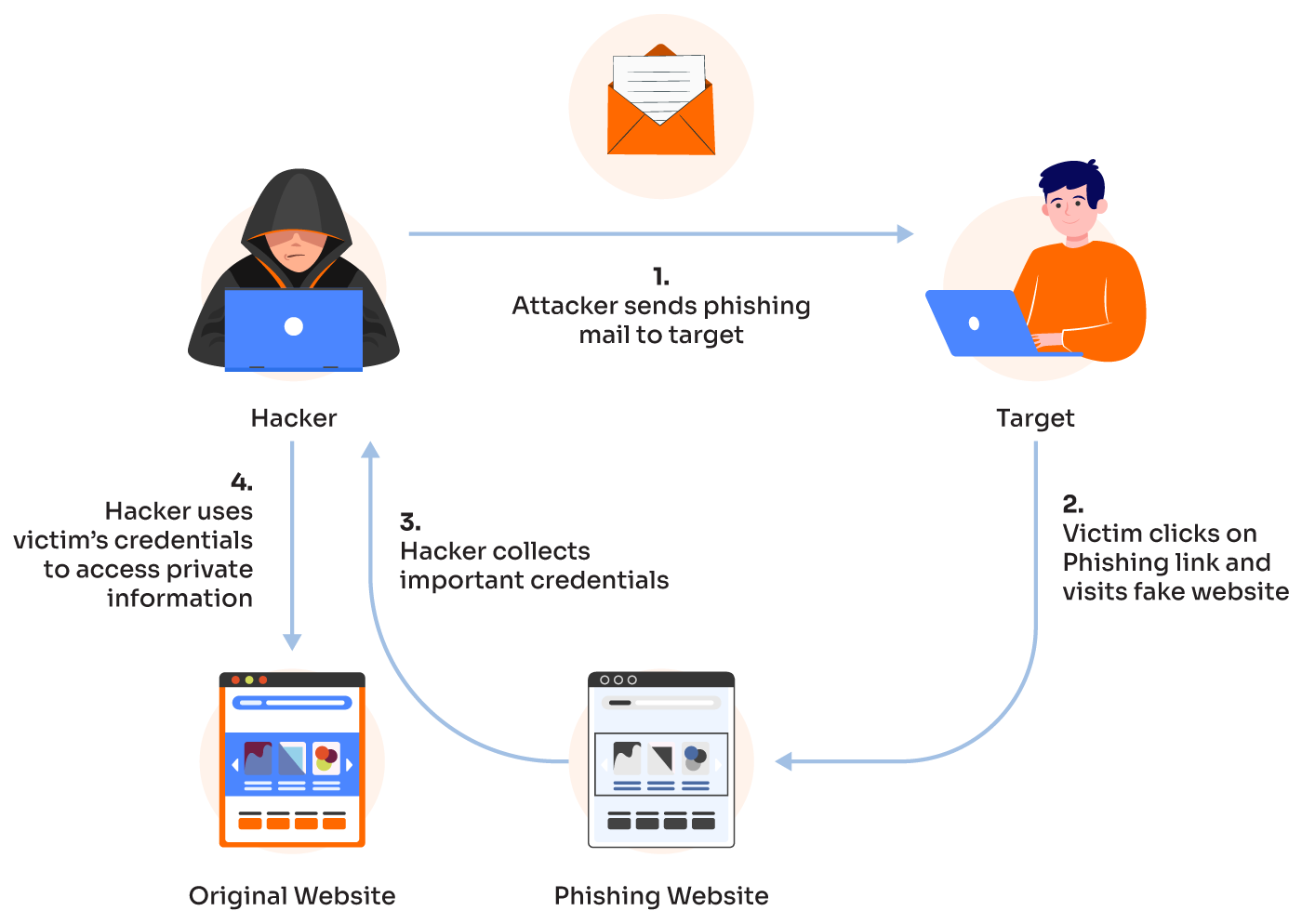{kind=link}
{kind=link}
{kind=link}
Leave A Comment